
Analysis based on 3,310 review comments from 4 bots across a SaaS platform frontend and backend. November 2025 to March 2026. ⚠️ AI tools move fast. This is a snapshot, not a permanent truth.
This is a write-up from four months of internal R&D. A SaaS platform was vibecoded with five AI models: the OpenAI Codex family, Claude Sonnet and Opus, Gemini, and Cursor's native Composer. Development was fast and the focus was on functionality. Code quality enforcement came from four AI code review bots acting as a second layer, an AI committee making sure AI-written code doesn't quietly break what's already working.
Tech stack context: Spring Boot on the backend and Angular on the frontend.
Every comment was extracted from GitHub, counted, and analyzed across 107 PRs over four months.
The dataset
Before reviewing the statistics: the bots did not run concurrently for the entire 4-month span, thus the totals should not be compared directly. CodeRabbit and Codex operated throughout most of the testing timeframe, while Cursor was active in the Dec–Jan window and PantoAI only during a short trial period.
| Bot | Active period | Review comments | Frontend | Backend |
|---|---|---|---|---|
| CodeRabbit | Dec 2025 – Mar 2026 | 2,477 | ~1,450 | ~1,027 |
| Cursor BugBot | Dec 2025 – Jan 2026 | 328 | ~160 | ~168 |
| PantoAI | Dec 2025 – Jan 2026 (trial only) | 273 | ~120 | ~153 |
| ChatGPT Codex | Nov 2025 – Mar 2026 | 232 | ~88 | ~144 |
(Inline review comments only; PR summaries and status messages were excluded.)
107 PRs had at least 2 bots active. 17 PRs had all 4. Those 17 are the only ones where any comparison is fair.
Bot by bot
 ChatGPT Codex — the business logic reviewer
ChatGPT Codex — the business logic reviewer
Codex was the only bot that regularly entered business and domain logic, not simply syntax or style.
It mostly operates on a P1/P2 severity scale, without much interest in style or formatting. Out of 232 comments, 116 were P1 critical and 67 were P2 major. When it flags something, it's usually serious.
What it caught that others missed:
-
Cross-tenant bypass — a slug-based endpoint had no permission check, unlike the identical ID-based one. Any authenticated user could read another tenant's data.
-
Admin creating cross-tenant resources — tenant validation returned immediately for admin roles, without actually validating anything. Silent Security Hole. The type of hole that is likely to pass human review as well, since it looks like it is performing some task.
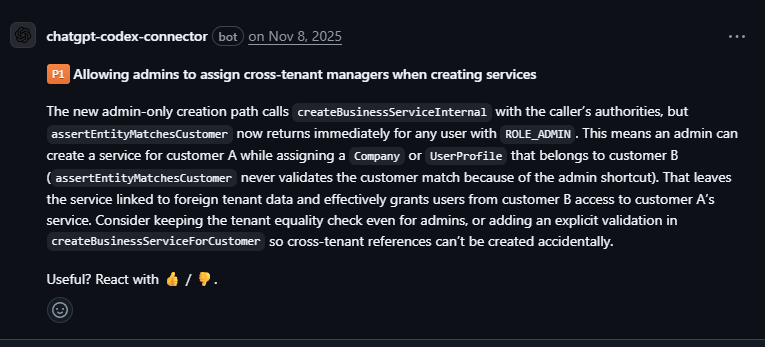
-
CSV export leaking data to restricted roles — every other listing endpoint in the same controller masked sensitive columns for restricted roles. The CSV export did not. Codex found the discrepancy in how the endpoints were processed by comparing the endpoints in the same file. What Codex specifically identified was the fact that it was not simply reading one method in isolation; it recognized the pattern across the entire controller.
In terms of front-end issues, Codex reviewed the following framework specific issues: undeclared animation triggers, SCSS syntax errors in inline styles, and incorrect signal dependencies in Angular.
After providing an instruction file describing the project's architectural patterns, Codex started catching PRs that drifted from the established structure. On a couple of occasions it flagged deviations before they got merged, which would've been much harder to untangle or detect afterwards.
On Codex Plus, the limit is roughly 10 review runs per week, and each run consumes quota. However, the 135 comments generated by Codex in November 2025 demonstrate the potential of Codex if there are no such limitations. While Codex is not expensive, the limit is noticeable when submitting PRs at a high frequency.
Most useful for systems with layered permissions and multi-tenant logic, where business rule violations are the most difficult to catch in review.
 Cursor BugBot — the regression catcher
Cursor BugBot — the regression catcher
Good at catching regressions, especially if you've added some new features that touch on parts of your application that were previously working.
Of 328 comments, 171 were High or Medium severity bugs. 157 were low severity notes. Nitpick culture doesn't exist here. 68 findings were directly regression-related, and the bot was active only in the Dec–Jan window.
What it caught:
-
AI-generated MULTIPLE_CHOICE can fail validation — defaults are added for
SINGLE_CHOICE, whileMULTIPLE_CHOICEstill requires explicit options. The generated question can pass generation and then fail on validation.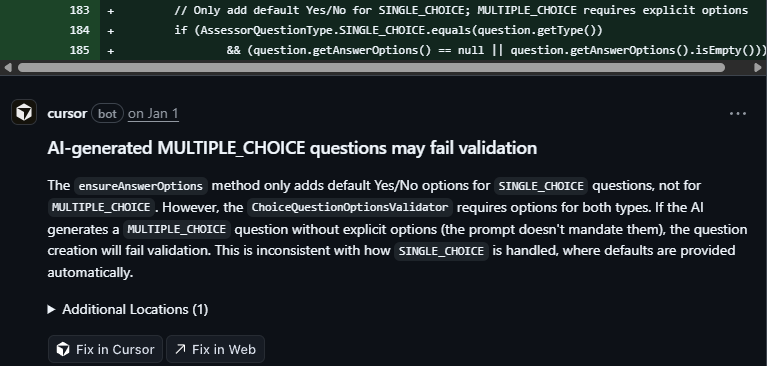
-
Validation blocking all uploads — new key validation rejected keys containing
/. The system generates keys astenantId/resourceId/filename. Every single upload would fail. Silently. -
Pagination count — the method was using current page size as the total result count. Users could see a false total number of items and therefore broken navigation.
On the frontend side: a valueChanges subscription clearing the form state in edit mode, a computed() signal reading a plain property instead of a signal which never gets refreshed.
All bots take 7 – 15 minutes per PR based on size. If you run multiple bots then those waits stack up. Push, wait, fix, push, wait again — a PR that should take an hour can stretch into a full day. While running more bots gives you more coverage, it also gives you more iterations cycles. It is worth it, but you feel it.
This bot found the most silent issues that would have broken in production out of all the bots that we tested.
 PantoAI — high volume, but occasionally brilliant
PantoAI — high volume, but occasionally brilliant
A lot of the comments here contain "verify", "ensure", or "check". The pattern suggests it's commenting on what it sees in the changed files without much awareness of the broader codebase, which is something Codex and Cursor are better at.
"Verify that the service handles null values correctly before processing." "Ensure error handling is implemented for edge cases." "Check that the configuration doesn't expose sensitive endpoints."
The comments often are generally correct; however, the developer still needs to determine if the comment is relevant to the specific Pull Request (PR). Each comment requires a significant amount of effort to read, and therefore, a tired developer may simply ignore it.
However, there were some good moments. The best one was when PantoAI caught that a new method, setPasswordIfPresent(), on the create user path could create accounts without a password hash and therefore the new user would have no usable account and potentially a security gap. None of the other bots identified this issue. In addition to identifying the issue, PantoAI provided two potential solutions: check for a password hash and reject requests without one, or generate a temporary password, set activated to false, and send an invitation. This single comment had more actionable information than many of CodeRabbit’s “Critical” findings.
Additionally, PantoAI was very good on nits such as unused imports and TypeScript type safety, which is an area where it was able to provide more detail than CodeRabbit.
PantoAI was used only during the trial period, and the decision was made not to subscribe. 273 comments in a month was enough to draw conclusions.
The signal-to-noise ratio of PantoAI is low; however, the few good finds that occur tend to be very good.
 CodeRabbit — the consistency and style enforcer
CodeRabbit — the consistency and style enforcer
CodeRabbit was the loudest bot in this dataset: 2,477 comments (about 70% of all comments). It was intentionally configured to be aggressive.
Signal vs noise: 56% nitpick/trivial, 23% potential real bugs.
What CodeRabbit Does Well:
-
Consistency and consolidation — found repeated defaults, magic numbers, and duplicated patterns across files.
-
Accessibility — the only bot that consistently flagged ARIA issues (
aria-label,role="alert", and screen-reader metadata). 207 comments were in this category. -
UI quality — caught flickering and loading-state issues, such as clearing state before API responses were applied.
-
Outdated dependencies — the only bot that actively searches the web and flags outdated packages with known CVEs.
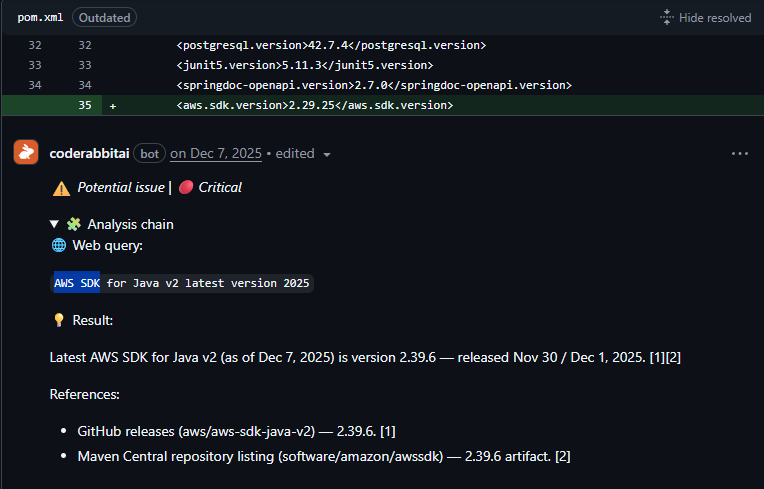
Where it falls short is regression detection. Cursor and Codex were more reliable there. CodeRabbit does catch regressions, but not like Cursor or Codex.
CodeRabbit is useful for consistency and code smell detection, but only with strict configuration. I wouldn't use it as the primary regression bot.
When all four look at the same code
Example: On a PR tightening authentication, all four bots commented on the same service file. Each saw something completely different:
| Bot | What it said |
|---|---|
| Cursor | Login uniqueness bypass — input normalized in validation but not in setters; two users can have the "same" login with different whitespace |
| PantoAI | Mapper overwrites activated to false when the flag isn't in the payload — every partial update silently deactivates the user |
| Codex | DTO ID copied directly into the entity on update — potential ID hijacking |
| CodeRabbit | isBlank() vs isEmpty() inconsistency, missing @Mapping(target = "id", ignore = true) |
Same Tools Different Focus
As mentioned previously, backend was where Codex and Cursor had the most successful runs identifying actual problems. The common themes among the backend runs included tenant isolation, role checks, and auth flows. CodeRabbit was primarily useful for null-safety and service layer consistency but rarely identified a security issue.
Frontend was CodeRabbit's domain:
- CodeRabbit: produced 1,524 comments on the Angular project, mostly about component consistency and style rules.
- Cursor: found framework-specific bugs, mostly around signal reactivity and form state.
- Codex: caught small but build-breaking mistakes, such as wrong SCSS syntax in inline styles and undefined animation triggers.
Summary
No bot replaces human review. But every bot replaces a specific type of human reviewer. That's a more useful way to think about it.
| Role | Bot | Note |
|---|---|---|
| Security & business logic | Codex | The only one that understands what the code should do |
| Regression detection | Cursor | Fastest for "what does this break" |
| Consistency & style | CodeRabbit | With configuration; without it, just noise |
| Coverage & Security | PantoAI | High noise, but occasionally catches what others miss |
What no bot provided was architectural feedback. None flagged that a service was doing too much or that a component was getting bloated. CodeRabbit is the only one that encourages writing tests, which is valuable. But without context on why this specific code is risky, it's incomplete guidance.
False positives
There are two types of false positives that we encountered time and time again. First, Cursor flagged SCALE as a regression risk when it was removed from an enum — it was correct about the mechanism of breaking existing database records on load when removing a string-stored enum value, but completely unaware of the fact that SCALE was a hallucination from an AI session in the past and never a required attribute.
Second, Codex continuously warned us about edits to existing Liquibase changesets. It was also correct in production — editing applied changesets breaks checksum validation. However, we weren’t deployed yet, so restructuring our migrations was okay. Codex had no idea that was the case.
There were other false positives too, but they were minor and not worth addressing one by one.
A bot doesn’t know where you are in your project lifecycle. A bot flags what looks like a problem most times, and the developer supplies the context.
What actually gets used
Bots are worth using, especially on a vibecoded codebase where code quality enforcement is not the top priority. Every bot has configuration — CodeRabbit through a dashboard, Cursor through BUGBOT.md, Codex through its own instruction file — and every well-configured bot will catch predictable issues automatically so developers can spend their time on things that require some level of judgment.
Running all four on larger PRs can mean 30+ comments in a single pass. That volume leads to notification fatigue and missed findings. One or two well-configured bots is more practical than four noisy ones.
The day-to-day setup here is Codex and Cursor: Codex for business logic and security, Cursor for regressions. CodeRabbit is worth the $15/month for consistency enforcement and code smell detection, particularly with the agent prompt feature for agentic workflows. PantoAI is worth a trial, not a subscription. Codex limits are the main friction — roughly 10 PR reviews per week on the Plus plan, which is noticeable on an active project.
Based on 3,310 review comments (3,785 total from GitHub; the remainder are PR summaries and status messages). November 2025 to March 2026.