
As a backend developer, I've been testing and using AI coding agents for the past ten months, exploring a tool that can solve problems independently. Here is my experience with different models through time:
Models tested:
- Gemini 2.5 Pro (10 months of usage)
- Claude Sonnet 3.7 → 4 → 4.5 (7 months across versions, latest update in October 2025)
- OpenAI GPT series: GPT-o3, GPT-5 variants (varying periods, GPT-5-codex for 7 weeks)
The tools I've been using:
- Cursor: IDE with integrated AI models
- Claude Code CLI: Command-line tool for Claude models
- Codex CLI: OpenAI command-line tool (uses GPT-5-codex model)
- Google AI Studio: Web interface for Gemini

Overview
Before I begin: I've been testing coding agents for over ten months on the backend projects. This review covers the models I've used long enough to provide an assessment: Claude Sonnet, Gemini, and OpenAI GPT series. Although more powerful models, such as Opus 4.1 and others, exist, my analysis focuses on tools that are less costly and more practical for day-to-day use. These are snapshots of experiences over time, not a definitive score. The models are constantly changing, and the experiences of various users may differ.
Timeline Summary
| Period | Model | Status | Duration |
|---|---|---|---|
| Jan to Oct 2025 | Gemini 2.5 Pro | Shifted to brainstorming only | 10 months |
| Feb to Apr 2025 | Claude Sonnet 3.7 | Used for a short period | 3 months |
| Jul to Sep 2025 | Claude Sonnet 4 | Active for small tasks | 3 months |
| Aug 2025 | GPT-o3 | Failed test | Few days |
| Sep 2025 | GPT-5 | Debugging during transition | 4 weeks |
| Sep to Oct 2025 | GPT-5-codex | Primary tool for heavy lifting | 7 weeks |
| Oct 2025 | Claude Sonnet 4.5 | Edits across multiple files | 4 weeks |
Claude Sonnet 3.7 → 4 → 4.5
Time of use: 7 months across versions
Tools: Cursor IDE and Claude Code CLI
Claude Sonnet used to be my primary AI assistant. I started with version 3.7, moved to Sonnet 4, and in October 2025 rolled into Sonnet 4.5. I now lean on GPT-5-codex for the heavy lifting, yet Claude Code stays in daily rotation when I need fast edits and tight tooling.
Advantages
Claude shows excellent results on specific, well-defined tasks. Prompts that include refactoring functions, optimizing queries, and implementing error handling are handled very well. It has proven useful when implementing feedback from the code review process, where it can understand the context and apply the changes. Sonnet 4.5 also adds a noticeable speed boost when you edit multiple files with focused, simple changes.
The Claude Code CLI offers better navigation between different directories and repositories, simplifying work on projects with multiple codebases.
Challenges
When working with more complex or abstract requirements, I have noticed that the model provides too complicated solutions. That reflects in ignoring existing components and creating redundant code. If there were an existing method that could've been extended with additional arguments, Claude would make a new function that performed the same job, instead of redefining the existing function. That may result in creating more lines of code, nested loops, and redundant checks. Sonnet 4.5 keeps that pattern. You gain speed, yet you do not gain extra quality on the hardest tasks.
To solve this problem, I made a ruleset file (Claude.md) with over a thousand lines of coding standards and project structure information. However, the model often disregarded the rules, so I had to monitor its work constantly and steer its course.
Differences Between Environments
The thinking mode Sonnet 4 in the Claude Code CLI can produce better solutions for complex problems, whereas in the Cursor IDE, it may modify parts of the code that are not relevant to the task. Sonnet 4.5 keeps that split. The CLI gives you the most predictable edits while Cursor still feels risky.
Why I Still Pair Claude Code With Codex
Claude Code keeps a spot in my toolkit because it offers features you still cannot get in Codex CLI. You get a clear bash command permission flow, rollbacks tied to each conversation, quick switches between approval modes, the ability to send a message while the model works, session wide command approvals, agent management, a real plan mode, skills that load context on demand, and sandbox feedback that explains failures. Codex still frustrates me when it keeps asking for the same approvals or when sandbox errors show up without context, and it often prefers Python snippets over bash commands, which makes permissions harder to audit. Those touches make short edits easier even while Codex handles your heavy work. You get the best balance when you let Codex own the deep fixes and ask Claude Code to finish the rapid polish.
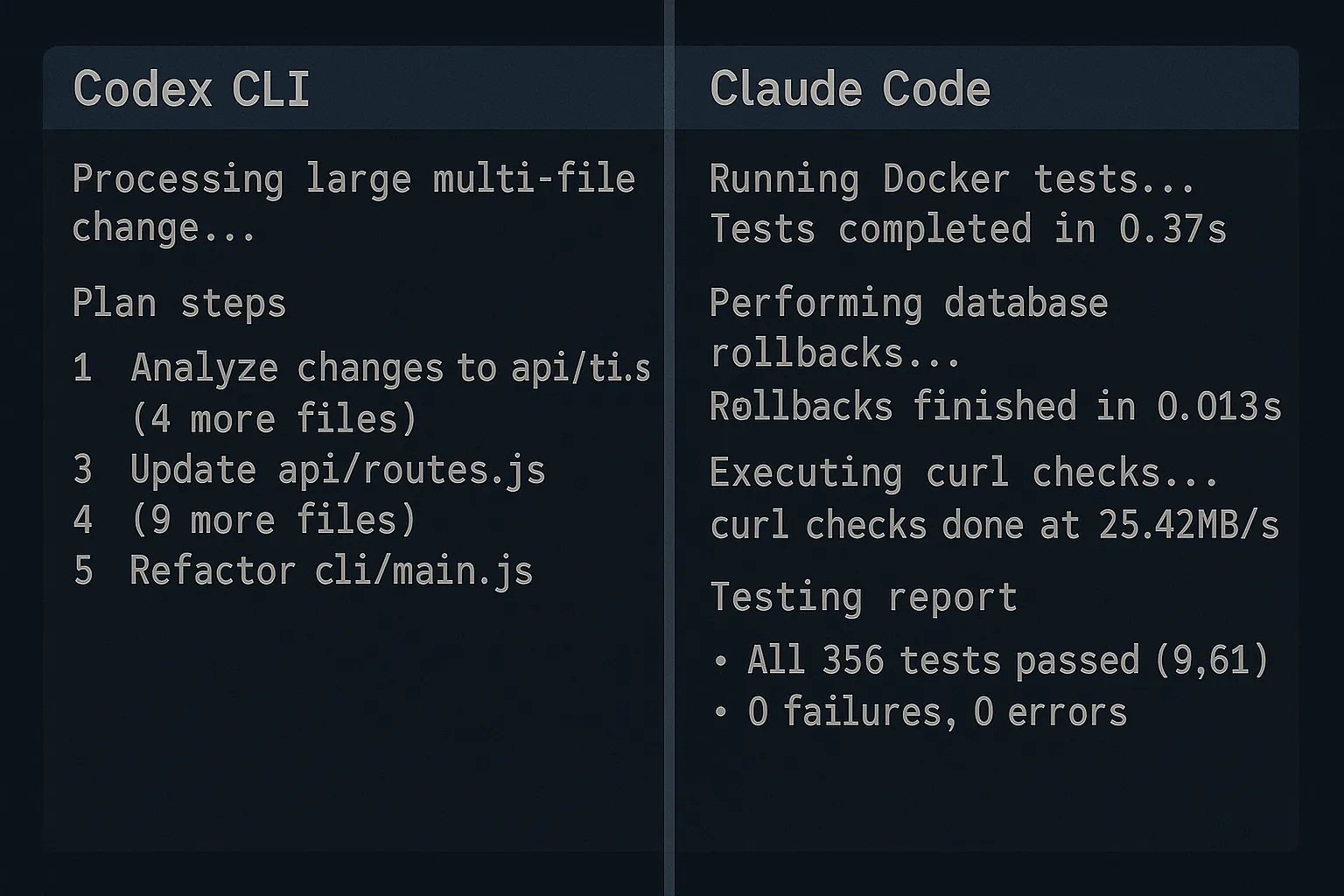
Claude Code now handles most of my testing. I hand Codex the implementation and send the same request to Claude Sonnet with a testing script. It runs inside Docker, tweaks the test database, executes curls, compares results, rolls back migrations, and hands me a clean report. Codex cannot replace that workflow yet, so Claude stays in the loop.
Recommendation
Use Claude Sonnet as an assistant while you stay actively involved in the process. It speeds up routine tasks such as refactoring, writing unit tests, and minor code changes. For complex implementations, keep monitoring and validate the generated code before you trust it.
Gemini 2.5 Pro
Time of use: 10 months
Tools: Google AI Studio, Cursor IDE, and Gemini CLI
Gemini 2.5 Pro is one of the first models I've been using and testing. After ten months of usage, it appears to be the tool with unique characteristics that set it apart from the competition.
Advantages
Gemini excels in conceptual work and brainstorming sessions. What I appreciate most about it is its ability to provide constructive pushback, unlike most models that often accept suggestions and agree with the user. Gemini will stick with its approach when it believes it's the most optimal. These characteristics have proven to be very worthy when making architectural decisions or business planning.
In the initial period of use through Cursor, Gemini demonstrated good ability to solve complex problems, even though they were very challenging for Sonnet 3.7. I was able to have long sessions, all the while, with remarkable context management.
Challenges
Unfortunately, the quality of work through Cursor got worse over time. The model began entering endless thinking cycles without concrete output, and the frequency of hallucinations increased. It created references to functions and models that weren't even present in the codebase. These problems led me to try Gemini CLI, which appears powerful on paper with an enormous context window. However, due to the previous negative experiences, I haven't gained enough confidence to use it for critical tasks.
The Differences Between the Environments
- Google AI Studio: Remained reliable for high-level planning and ideation
- Cursor integration: Became unpredictable
- Gemini CLI: Despite impressive specifications, its use is limited because of a lack of confidence
Recommendation
Gemini 2.5 Pro remains my number one tool for business discussions and planning. It's worth using in the beginning phases of the project. For implementation and coding, I would recommend different options that are generally more predictable.
OpenAI GPT Models (o3, GPT-5, GPT-5-codex)
Time of use: Varies by model (GPT-5-codex - 7 weeks, GPT-5 - 4 weeks)
Tools: Cursor IDE and Codex CLI
I've tested several OpenAI models over time, with different experiences depending on version and environment.
GPT-o3 in Cursor
My experience with the GPT-o3 model was short. After several successful prompts, the tipping point came when I gave it one prompt: it took a long time to think, make a change, think again, and then undo the exact change. After that, it continued to insist that the problem had been fixed. This event led me to stop using the O3 model for any work on the production codebase.
GPT-5 in Cursor
Transitioning to GPT-5 brought a massive improvement. The model demonstrates good reasoning abilities and confidence when navigating a complex codebase, maintaining quality even when faced with challenges or requiring reconsideration. Although it sometimes requires more processing time, it has proven reliable for debugging and maintains solid context management over longer sessions.
GPT-5-Codex in Codex CLI
When I switched to the Codex CLI tool, I began experimenting with various GPT-5 variants, including the latest GPT-5-codex model. This model hits a sweet spot for me. It now handles most of my heavy lifting while Claude Code owns the quick edits. The turning point was the task of creating a production database script. After several hours and multiple iterations, GPT-5-codex generated a functional script of approximately 1,000 lines that functioned exactly as specified. It was the first time I could fully trust AI-generated code for a critical task. The model adhered to the design rules and specifications, with no deviations from the intended design.
Challenges
The main disadvantage of the GPT-5-codex model is the handling of direction changes during development. When I break and change access, it often leaves traces of old code that must be manually cleaned up. Claude, by comparison, more elegantly discards the old logic. However, this is a minor inconvenience compared to the quality that GPT-5-codex provides.
Recommendation
For complex tasks that require a deep understanding of the project, GPT-5-codex (via the Codex CLI) is currently my most powerful tool. Standard GPT-5 through Cursor remains a solid option for debugging. I do not recommend GPT-o3 for production work based on my experience.
Same Task, Different Outputs
To compare the models more objectively, I assigned a production requirement: implementing automatic Voice AI call filtering based on statuses from an external system.
GPT-5-codex (via Codex CLI): Although his process was the longest, he provided the most concrete and practical plan. He precisely identified which parts of the code needed to be changed, proposed a centralized place for new logic, and included some recommendations. He planned to keep changes as small as possible while still making them count, laying them out step by step.
Claude Sonnet 4 (via Claude Code CLI): In a short time, he created a system ready for heavy workloads, with entirely new architectural layers and interfaces. The proposal was detailed, but significantly more complex than the task required, as if he were building the foundation for a new product.
Gemini 2.5 Pro (via Gemini CLI): He produced the quickest answer, though it was fairly superficial. The output contained pseudo-code, offering a useful snapshot of the idea, but it was insufficient for starting real development work.
Key Takeaway
The processing time does not correlate with the quality of the solution. GPT-5-codex, although the slowest, provides the most balanced answer because it stays detailed enough to implement without adding extra noise. Claude shines when you need clean small changes and you already know where the fix lives. Gemini gives quick drafts for prototyping and brainstorming.
Comparison Table
| Model | Best for | Strengths | Weaknesses |
|---|---|---|---|
| GPT-5-codex | Complex tasks, implementation, and debugging | Precision, deep code understanding | Slower, awkward when changing direction |
| Claude Sonnet 4 | Routine tasks, minor refactoring | Speed, navigation | Tendency towards complication, disregarding existing logic |
| Claude Sonnet 4.5 | Quick edits across multiple files | Fast on small batches of changes, strong testing workflow | No quality gain on complex work |
| Gemini 2.5 Pro | Brainstorming, architectural decisions, planning | Conceptual thinking, 'pushback' on bad ideas | Unpredictable for coding, prone to hallucinations |
Personal Reality Check
These AI agents generate hundreds or thousands of lines of code in minutes. I often find myself in situations where I simply cannot read and understand everything they've produced in the time available. This is both powerful and dangerous.
This is the trade-off with AI-assisted development today: you gain speed, but you give up some degree of complete understanding.
My Approach Now
- For critical paths: review every line, with no exceptions
- For boilerplate/tests: check patterns and edge cases
- For exploratory code: run tests instead of line-by-line review
- Always: keep the ability to debug what you didn't write
Which Model is the Best?
Choosing a single winner can be difficult because it depends on the use case. Claude Code Sonnet 4.5 stays fast and maneuverable, so you can lean on it for quick edits that touch several files and for running the testing loop. Gemini provides the best support in high-level business planning and brainstorming. Codex gives the best results when working on complex issues that require in-depth knowledge of the project or debugging.
Ultimately, there is no single "best model." The key is knowing when to use each of their unique capabilities. Use the right tool at the right time and you will feel the difference.